Background
Notation
- 大写字母X表示随机变量
- 大写P(X)表示随机变量的概率分布
- x∼P(X)表示从概率分布中采样出某个值x
- 小写p(X)表示随机变量X的概率密度函数
- p(X=x)表示某一点x处的概率值
Bayesian
贝叶斯公式:
p(Z∣X)=p(X)p(X∣Z)p(Z)
其中,p(Z∣X)被称为后验概率(posterior probability),p(X∣Z)被称为似然函数(likelihood),p(Z)被称为先验概率(prior probability),p(X)是边缘似然概率。
Likelihood
定义:The likelihood function (often simply called the likelihood) describes the joint probability of the observed data as a function of the parameters of the chosen statistical model. For each specific parameter value θ in the parameter space, the likelihood function p(X∣θ) therefore assigns a probabilistic prediction to the observed data X.
总结一下上面定义的关键点:
- 似然不是概率,尽管它看起来像个概率分布,它的加和不是1,似然p(X∣Z)是关于Z的函数,是给定X变化Z的概率
- 一般情况,我们选定似然函数的形式,比如假设Z就是高斯分布的μ,σ,我们来变换不同的μ,σ,得到不同参数分布下得到X的概率,换句话说,一般似然函数是可计算的
- 和条件概率的区别:哪个变量是固定哪个变量是变化的:条件概率p(X∣Z)中Z是固定的,X是变化的;似然函数p(X∣Z),正相反,X是固定的,Z是变化的。
Expecation
离散的随机变量z,服从分布z∼Qϕ(Z∣X)(注意这个概率分布假定X是给定的,Z是变化的)。关于随机变量x的函数f(z)的期望定义:
Ez∼Qϕ(Z∣X)[f(z)]=z∑qϕ(z∣x)⋅f(z)
其中,qϕ(z∣x)是取到某个z的概率值。另外,∑zqϕ(z∣x)=1
Variational Inference
变分推断(Variational Inference)是指通过优化方法“近似”后验分布的过程。
我们都有后验概率的解析式p(z∣x)=p(x)p(x∣z)p(z),为什么不能直接计算后验概率而要近似呢?
依次来看似然p(x∣z),先验p(z)和边缘似然p(x):
- 似然p(x∣z): 一般是假设已知似然函数的形式,例如高斯分布
- 先验p(z): 一般也可以估计,例如统计大量数据中猫的图片的数量占比,即为先验
- 边缘似然p(x): 在高维的情况下,计算边缘似然p(x)是非常困难的
边缘似然p(x)的定义是p(x)=∑zp(x∣z)p(z),如果z是高维度向量z=(z1,z2,...,zn),每个维度zi有非常多可能的取值,要遍历所有的z,计算p(x)是非指数级时间复杂度。
因此,变分推断通过引入一个参数化的近似分布qϕ(z),通过优化方法是其逼近真实的后验分布p(z∣x)。
Evidence Lower Bound (ELBO)
以下的推导来自这篇博客1。我们定义一个参数化的分布Qϕ(Z∣X)(假设是高斯分布),通过调整参数ϕ来近似P(Z∣X),例如下图:
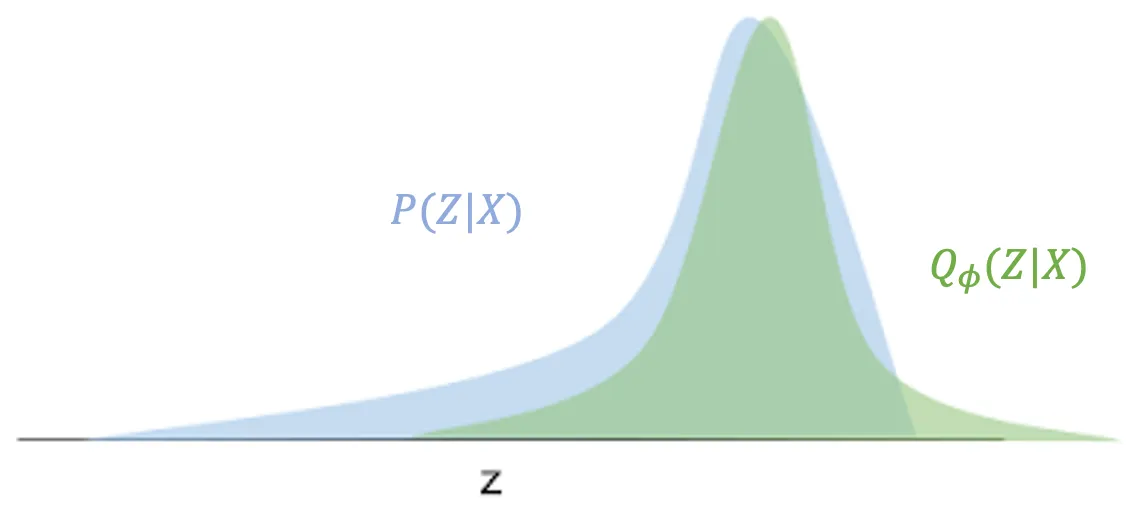
如何“近似”呢?当然是分布间的距离,这里采用了Reverse KL,对离散的z(P(Z∣X)中X是观测量固定值,Z是随机变量)进行求和:
KL(Qϕ(Z∣X)∣∣P(Z∣X))=z∈Z∑qϕ(z∣x)logp(z∣x)qϕ(z∣x)
为什么说是反向Reverse呢?因为我们的目标是P(Z∣X),“正向”应该是从P(Z∣X)看与Qϕ(Z∣X)的距离,即KL(P(Z∣X)∣∣Qϕ(Z∣X))。使用Reverse KL的原因在下节。
对KL各种展开推导:
KL(Q∣∣P)=z∈Z∑qϕ(z∣x)logp(z,x)qϕ(z∣x)p(x)=z∈Z∑qϕ(z∣x)(logp(z,x)qϕ(z∣x)+logp(x))=(z∑qϕ(z∣x)logp(z,x)qϕ(z∣x))+(z∑logp(x)qϕ(z∣x))=(z∑qϕ(z∣x)logp(z,x)qϕ(z∣x))+(logp(x)z∑qϕ(z∣x))=logp(x)+(z∑qϕ(z∣x)logp(z,x)qϕ(z∣x))via p(x,z)=p(z∣x)p(x)via ∑zq(z)=1
最小化KL(Q∣∣P)就是最小化上面公式中的第二项,因为logp(x)是固定的。然后我们把第二项展开(引入了期望的定义):
z∑qϕ(z∣x)logp(z,x)qϕ(z∣x)=Ez∼Qϕ(Z∣X)[logp(z,x)qϕ(z∣x)]=EQ[logqϕ(z∣x)−logp(x,z)]=EQ[logqϕ(z∣x)−(logp(x∣z)+log(p(z)))]=EQ[logqϕ(z∣x)−logp(x∣z)−log(p(z)))](via logp(x,z)=p(x∣z)p(z))
最小化上面,就是最大化它的负数:
maximize L=−z∑qϕ(z∣x)logp(z,x)qϕ(z∣x)=EQ[−logqϕ(z∣x)+logp(x∣z)+log(p(z)))]=EQ[logp(x∣z)+logqϕ(z∣x)p(z)]
上面公式还可以进一步推导变得更直观:
L=EQ[logp(x∣z)+logqϕ(z∣x)p(z)]=EQ[logp(x∣z)]+Q∑q(z∣x)logqϕ(z∣x)p(z)=EQ[logp(x∣z)]−KL(Q(Z∣X)∣∣P(Z))Definition of expectationDefinition of KL divergence
在VAE中,从z∼Q(Z∣X)采样是所谓的Encoding过程,即将样本X压缩到隐变量z,从x∼Q(X∣Z)中采样是Decoding过程,即生成或恢复样本x。
从上面公式可知,L是两部分的加和,第一部份是decoding的似然函数的期望,即衡量变分分布可以从隐变量Z从解码回到X的好坏,第二部分是我们用于逼近真实分布的变分分布Q(Z∣X)于隐变量的先验P(Z)的KL散度。如果我们假定Q(Z∣X)的形式是条件概率高斯分布,那么先验P(Z)经常选取的是标准高斯分布,即均值为0和方差是1。
带入初始的公式(1),会得到:
KL(Q∣∣P)=logp(x)−L
由于KL(Q∣∣P)≥0,所以必然有logp(x)≥L,L就被称为变分下界(variational lower bound),或Evidence Lower Bound (ELBO),我们需要知道到底是针对什么的下界,它是logp(x)=log∑zp(x∣z)p(z),即模型生成观测x的能力。
回到变分推断的优化目标,如果要最小化KL(Q∣∣P),即要最小化−L,因此损失函数是:
Loss=−L=−EQ[logp(x∣z)]+KL(Q(Z∣X)∣∣P(Z))
Forward KL vs. Reverse KL
前面说过,在使用变分分布Q(Z∣X)来逼近真实后验分布P(Z∣X)时,我们使用的是Reverse KL,即KL(Q∣∣P)。原因是什么呢?
如果选择Forward KL:
KLfwd(P∣∣Q)=Ez∼P[logq(z)p(z)]
我们不必展开过多,上面公式中已经有困难存在:z需要从真实后验P(Z∣X)中采样,这是不可能的,因为真实后验我们不知道。
除了上面的困难,还有优化不稳定的问题。
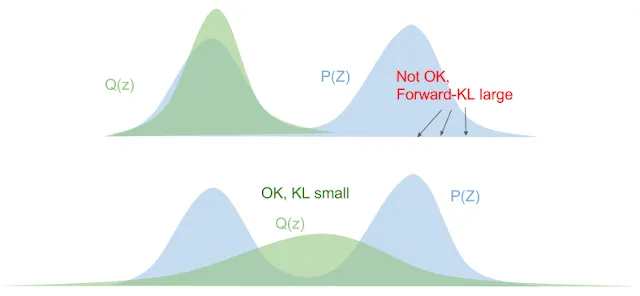
上面公式中q(z)p(z),如果真实后验p(z)>0,但是变分分布q(z)比如说接近0,会导致q(z)p(z)的值变得无穷大,即q(z)需要支撑(support)p(z)区域,否则优化就爆炸了,这会导致变分分布q(z)在优化过程中避免0出现(zero-avoiding),见下图:
那Reverse KL是什么情况呢?
KLrev(Q∣∣P)=Ez∼Q[logp(z)q(z)]
当真实后验p(z)趋近于0,变分分布q(z)也会趋近于0,见下图:
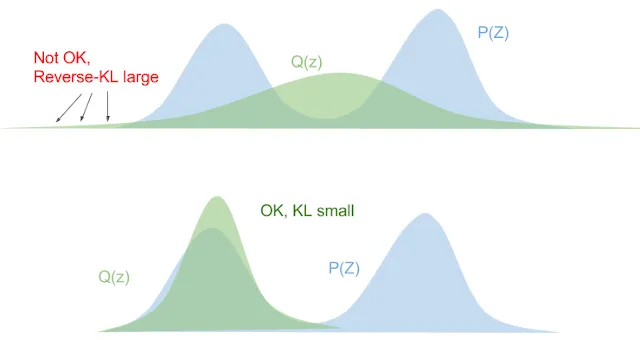
总结起来,最小化forward-KL会拉伸变分分布p(z)来覆盖掉整个真实后验p(z),而最小化Reverse KL会使得变分分布p(z)更挤进真实后验p(z)。
Variational Autoencoder
铺垫了很多终于要来到变分自编码器VAE了。Lil’Log的文章2比较了多种Autoencoder,同时也包含VAE,建议去认真阅读。
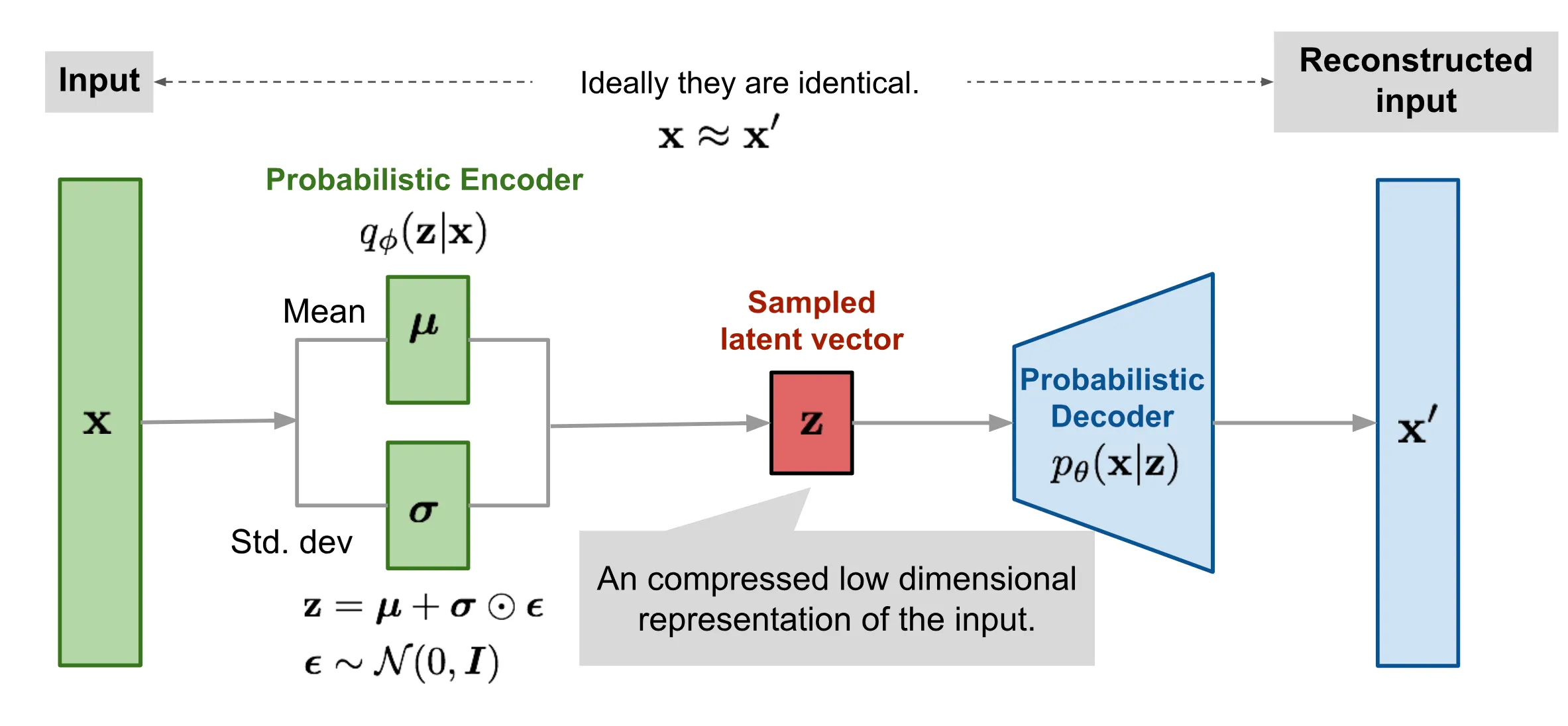
自编码器一般由两部分构成:编码器和解码器。解码器负责将高维数据压缩到一个隐变量(latent code),相当于对高维数据的降维;解码器负责从隐变量恢复出输入的高维数据数据,注意是恢复,而不是生成。但是,VAE和AE相比非常不一样,VAE是一个“生成式”模型。VAE的编码器将高维数据压缩到一个隐空间的分布中,从分布中采样,解码器负责从新的采样中恢复(生成)和输入数据不同的数据!
我们设输入数据为X,隐变量为Z,隐变量Z所在的分布使用P(Z)来表示,生成模型的核心任务是学习数据的分布P(X),从而能够生成与真实数据分布一致的新样本Xnew,但是直接建模高维数据X的分布十分困难,原因在于高维数据计算复杂,以及数据X中隐含的潜在变量(如物体的形状、光照条件)未被显式建模。解决方案是引入隐变量Z,通过隐变量控制生成:P(X∣Z)P(Z),具体来说:
- 概率编码器P(Z∣X)把输入X=x压缩到隐空间的分布P(Z)
- 从隐空间Pθ(Z)中采样新隐变量znew
- 概率解码器P(X∣Z)基于隐变量znew生成xnew
即:
xnew∼P(X)=∑p(x∣z)p(z)dz
为什么是对z的求和(积分)?通过对Z求和(积分),模型生成的X不再依赖于某个特定的Z,而是覆盖所有可能的Z值,从而匹配真实数据分布P(X)。
上面公式,和前面的边缘似然的定义是一致的,并且在变分方法的推导中,我们知道logp(X)≥ELBO,即我们需要最小化−ELBO:
LVAE=−Ez∼qϕ(z∣x)logpθ(x∣z)+DKL(qϕ(z∣x)∥pθ(z))
Reparameterization Trick
上面的损失函数放到深度学习的语境下存在一个问题,采样过程z∼qϕ(z∣x)是一个随机过程,不可微,没有办法使用反向传播来更新梯度。于是,引入一个技巧,称为重参数化技巧。
VAE中假设qϕ(z∣x)的形式是多元高斯分布
z∼qϕ(z∣x)=N(μ,σI)
经过gθ(ϵ)重参数化之后:
z=μ+σ⊙ϵ, where ϵ∼N(0,I); Reparameterization trick.
其中⊙意味着元素相乘。
如此,梯度变得可计算:
∂μ∂L∂σ∂L=Eϵ∼N(0,1)[∂z∂L⋅∂μ∂z]=Eϵ[∂z∂L⋅1]=Eϵ∼N(0,1)[∂z∂L⋅∂σ∂z]=Eϵ[∂z∂L⋅ϵ]
最后,使用博客2中的图更直观的表示VAE: