Position Encoding是Transformer 重要组成部分,输入序列通过加入对输入位置编码后的信息,使模型有能力分辨不同位置的能力,主要有绝对位置编码 和相对位置编码 。本文是对苏神的Transformer升级之路系列 1 2 3
深入三角函数位置编码
位置编码在Transformer原文中的戏份并不多,主要目的是由于自注意力attention的操作是不区分位置的,因此我们需要让模型知道,例如这是第几个词(绝对位置),这个词和另一个词的距离(相对位置)。
虽然知道三角函数位置编码的具体公式和代码,但是很多细节和设计理由并没有深究,比较简单的两个问题是:
位置编码是如何给输入Embedding序列注入位置信息的? 为什么使用相加赋予输入Embedding序列位置信息?
位置编码性质
回顾一下三角函数位置编码:
{ p k , 2 i = sin ( k / 10000 2 i / d ) p k , 2 i + 1 = cos ( k / 10000 2 i / d ) \begin{equation}\left\{\begin{aligned}\boldsymbol{p}_{k,2i}&=\sin\Big(k/10000^{2i/d}\Big)\\
\boldsymbol{p}_{k, 2i+1}&=\cos\Big(k/10000^{2i/d}\Big)
\end{aligned}\right.\end{equation} ⎩ ⎨ ⎧ p k , 2 i p k , 2 i + 1 = sin ( k /1000 0 2 i / d ) = cos ( k /1000 0 2 i / d ) 其中,p k , 2 i , p k , 2 i + 1 p_{k,2i},p_{k,2i+1} p k , 2 i , p k , 2 i + 1 k k k embed_dim上的2 i , 2 i + 1 2i,2i+1 2 i , 2 i + 1 d d d embed_dim的大小。
换一种形式可以看到,每个对序列k k k p k \boldsymbol{p}_{k} p k sin \sin sin cos \cos cos
p k = [ sin ( ω 0 ⋅ k ) cos ( ω 0 ⋅ k ) sin ( ω 1 ⋅ k ) cos ( ω 1 ⋅ k ) ⋮ sin ( ω d 2 − 1 ⋅ k ) cos ( ω d 2 − 1 ⋅ k ) ] \begin{equation}
\boldsymbol{p}_{k} = \begin{bmatrix}
\sin({\omega_0} \cdot k)\\
\cos({\omega_0} \cdot k)\\
\\
\sin({\omega_1} \cdot k)\\
\cos({\omega_1} \cdot k)\\
\\
\vdots\\
\\
\sin({\omega_{\frac{d}{2}-1}} \cdot k)\\
\cos({\omega_{\frac{d}{2}-1}} \cdot k)
\end{bmatrix}
\end{equation} p k = sin ( ω 0 ⋅ k ) cos ( ω 0 ⋅ k ) sin ( ω 1 ⋅ k ) cos ( ω 1 ⋅ k ) ⋮ sin ( ω 2 d − 1 ⋅ k ) cos ( ω 2 d − 1 ⋅ k ) 其中,ω i = 1 10000 2 i / d \omega_i = \frac{1}{10000^{2i / d}} ω i = 1000 0 2 i / d 1 奇数和偶数位分别是频率相同的sin \sin sin cos \cos cos ,后面的RoPE会使用这一个二维向量举例。
为什么上式赋予了Embedding位置信息?
我们先回到问题的原点,如果想要给某个序列添加位置信息,这个位置信息是什么样子的呢?
有一些选项:
例如[ 0 , 1 ] [0,1] [ 0 , 1 ]
或者,可以把位置这个数字直接给到序列,即1 , 2 , . . . , n 1,2,...,n 1 , 2 , ... , n
总结起来,给序列提供位置信息需要的性质:
每个序列位置的位置编码应该是唯一的
必须是确定性的,是序列位置k k k
很多文章使用二进制的数字来表示整型的位置4
0 : 0 0 0 0 8 : 1 0 0 0 1 : 0 0 0 1 9 : 1 0 0 1 2 : 0 0 1 0 10 : 1 0 1 0 3 : 0 0 1 1 11 : 1 0 1 1 4 : 0 1 0 0 12 : 1 1 0 0 5 : 0 1 0 1 13 : 1 1 0 1 6 : 0 1 1 0 14 : 1 1 1 0 7 : 0 1 1 1 15 : 1 1 1 1 \begin{align}
0: \ \ \ \ \color{orange}{\texttt{0}} \ \ \color{green}{\texttt{0}} \ \ \color{blue}{\texttt{0}} \ \ \color{red}{\texttt{0}} & &
8: \ \ \ \ \color{orange}{\texttt{1}} \ \ \color{green}{\texttt{0}} \ \ \color{blue}{\texttt{0}} \ \ \color{red}{\texttt{0}} \\
1: \ \ \ \ \color{orange}{\texttt{0}} \ \ \color{green}{\texttt{0}} \ \ \color{blue}{\texttt{0}} \ \ \color{red}{\texttt{1}} & &
9: \ \ \ \ \color{orange}{\texttt{1}} \ \ \color{green}{\texttt{0}} \ \ \color{blue}{\texttt{0}} \ \ \color{red}{\texttt{1}} \\
2: \ \ \ \ \color{orange}{\texttt{0}} \ \ \color{green}{\texttt{0}} \ \ \color{blue}{\texttt{1}} \ \ \color{red}{\texttt{0}} & &
10: \ \ \ \ \color{orange}{\texttt{1}} \ \ \color{green}{\texttt{0}} \ \ \color{blue}{\texttt{1}} \ \ \color{red}{\texttt{0}} \\
3: \ \ \ \ \color{orange}{\texttt{0}} \ \ \color{green}{\texttt{0}} \ \ \color{blue}{\texttt{1}} \ \ \color{red}{\texttt{1}} & &
11: \ \ \ \ \color{orange}{\texttt{1}} \ \ \color{green}{\texttt{0}} \ \ \color{blue}{\texttt{1}} \ \ \color{red}{\texttt{1}} \\
4: \ \ \ \ \color{orange}{\texttt{0}} \ \ \color{green}{\texttt{1}} \ \ \color{blue}{\texttt{0}} \ \ \color{red}{\texttt{0}} & &
12: \ \ \ \ \color{orange}{\texttt{1}} \ \ \color{green}{\texttt{1}} \ \ \color{blue}{\texttt{0}} \ \ \color{red}{\texttt{0}} \\
5: \ \ \ \ \color{orange}{\texttt{0}} \ \ \color{green}{\texttt{1}} \ \ \color{blue}{\texttt{0}} \ \ \color{red}{\texttt{1}} & &
13: \ \ \ \ \color{orange}{\texttt{1}} \ \ \color{green}{\texttt{1}} \ \ \color{blue}{\texttt{0}} \ \ \color{red}{\texttt{1}} \\
6: \ \ \ \ \color{orange}{\texttt{0}} \ \ \color{green}{\texttt{1}} \ \ \color{blue}{\texttt{1}} \ \ \color{red}{\texttt{0}} & &
14: \ \ \ \ \color{orange}{\texttt{1}} \ \ \color{green}{\texttt{1}} \ \ \color{blue}{\texttt{1}} \ \ \color{red}{\texttt{0}} \\
7: \ \ \ \ \color{orange}{\texttt{0}} \ \ \color{green}{\texttt{1}} \ \ \color{blue}{\texttt{1}} \ \ \color{red}{\texttt{1}} & &
15: \ \ \ \ \color{orange}{\texttt{1}} \ \ \color{green}{\texttt{1}} \ \ \color{blue}{\texttt{1}} \ \ \color{red}{\texttt{1}} \\
\end{align} 0 : 0 0 0 0 1 : 0 0 0 1 2 : 0 0 1 0 3 : 0 0 1 1 4 : 0 1 0 0 5 : 0 1 0 1 6 : 0 1 1 0 7 : 0 1 1 1 8 : 1 0 0 0 9 : 1 0 0 1 10 : 1 0 1 0 11 : 1 0 1 1 12 : 1 1 0 0 13 : 1 1 0 1 14 : 1 1 1 0 15 : 1 1 1 1 可以观察到:低位(红色)的0和1交替是非常快速的,越往高位走,0和1的交替频率会越低。0和1的交替都是整型,它的浮点数形式就想到了三角函数交替了。
相加
第二个问题:为什么和输入Embedding序列相加?Concat行不行?
tl;dr是其实concat应该也没有太大的问题,但是可能会增加一些参数量。
Reddit上有一个不错的回答[^6]:
In attention, we basically take two word embeddings (x and y), pass one through a Query transformation matrix (Q) and the second through a Key transformation matrix (K), and compare how similar the resulting query and key vectors are by their dot product. So, basically, we want the dot product between Qx and Ky, which we write as:
(Qx)‘(Ky) = x’ (Q’Ky). So equivalently we just need to learn one joint Query-Key transformation (Q’K) that transform the secondary inputs y into a new space in which we can compare x.
By adding positional encodings e and f to x and y, respectively, we essentially change the dot product to
(Q(x+e))’ (K(y+f)) = (Qx+Qe)’ (Ky+Kf) = (Qx)’ Ky + (Qx)’ Kf + (Qe)’ Ky + (Qe)’ Kf = x’ (Q’Ky) + x’ (Q’Kf) + e’ (Q’Ky) + e’ (Q’K f), where in addition to the original x’ (Q’Ky) term, which asks the question “how much attention should we pay to word x given word y”, we also have x’ (Q’Kf) + e’ (Q’Ky) + e’ (Q’K f), which ask the additional questions, “how much attention should we pay to word x given the position f of word y”, “how much attention should we pay to y given the position e of word x”, and “how much attention should we pay to the position e of word x given the position f of word y”.
Essentially, the learned transformation matrix Q’K with positional encodings has to do all four of these tasks simultaneously. This is the part that may appear inefficient, since intuitively, there should be a trade-off in the ability of Q’K to do four tasks simultaneously and well.
HOWEVER, MY GUESS is that there isn’t actually a trade-off when we force Q’K to do all four of these tasks, because of some approximate orthogonality condition that is satisfied of in high dimensions. The intuition for this is that randomly chosen vectors in high dimensions are almost always approximately orthogonal. There’s no reason to think that the word vectors and position encoding vectors are related in any way. If the word embeddings form a smaller dimensional subspace and the positional encodings form another smaller dimensional subspace, then perhaps the two subspaces themselves are approximately orthogonal, so presumably these subspaces can be transformed approx. independently through the same learned Q’K transformation (since they basically exist on different axes in high dimensional space). I don’t know if this is true, but it seems intuitively possible.
If true, this would explain why adding positional encodings, instead of concatenation, is essentially fine. Concatenation would ensure that the positional dimensions are orthogonal to the word dimensions, but my guess is that, because these embedding spaces are so high dimensional, you can get approximate orthogonality for free even when adding, without the costs of concatenation (many more parameters to learn). Adding layers would only help with this, by allowing for nonlinearities.
We also ultimately want e and f to behave in some nice ways, so that there’s some kind of “closeness” in the vector representation with respect to small changes in positions. The sin and cos representation is nice since nearby positions have high similarity in their positional encodings, which may make it easier to learn transformations that “preserve” this desired closeness.
(Maybe I’m wrong, and the approximate orthogonality arises from stacking multiple layers or non-linearities in the fully-connected parts of the transformer).
tl;dr: It is intuitively possible that, in high dimensions, the word vectors form a smaller dimensional subspace within the full embedding space, and the positional vectors form a different smaller dimensional subspace approximately orthogonal to the one spanned by word vectors. Thus despite vector addition, the two subspaces can be manipulated essentially independently of each other by some single learned transformation. Thus, concatenation doesn’t add much, but greatly increases cost in terms of parameters to learn.
相对性质
Transformer原文中有一句话:“We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset Δ d \Delta d Δ d p k + Δ d \boldsymbol{p}_{k+\Delta d} p k + Δ d p k \boldsymbol{p}_{k} p k 相对位置 ,但是如何证明?
翻译一下上面的表达到公式是说存在一个只与相对位置有关的T ( Δ d ) \boldsymbol{T}^{(\Delta d)} T ( Δ d )
T ( Δ d ) p k , : = p k + Δ d , : \boldsymbol{T}^{(\Delta d)}\boldsymbol{p}_{k,:}=\boldsymbol{p}_{k+\Delta d,:} T ( Δ d ) p k , : = p k + Δ d , : 文章5
T ( Δ d ) = [ Φ 0 ( Δ d ) 0 ⋯ 0 0 Φ 1 ( Δ d ) ⋯ 0 0 0 ⋱ 0 0 0 ⋯ Φ d 2 − 1 ( Δ d ) ] \boldsymbol{T}^{(\Delta d)} = \begin{bmatrix}
\boldsymbol{\Phi}^{(\Delta d)}_0 & \boldsymbol{0} & \cdots & \boldsymbol{0} \\
\boldsymbol{0} & \boldsymbol{\Phi}^{(\Delta d)}_1 & \cdots & \boldsymbol{0} \\
\boldsymbol{0} & \boldsymbol{0} & \ddots & \boldsymbol{0} \\
\boldsymbol{0} & \boldsymbol{0} & \cdots & \boldsymbol{\Phi}^{(\Delta d)}_{\frac{d}{2}-1}
\end{bmatrix} T ( Δ d ) = Φ 0 ( Δ d ) 0 0 0 0 Φ 1 ( Δ d ) 0 0 ⋯ ⋯ ⋱ ⋯ 0 0 0 Φ 2 d − 1 ( Δ d ) 其中,0 \boldsymbol{0} 0 2 × 2 2 \times 2 2 × 2 0 0 0 Φ m ( Δ d ) \boldsymbol{\Phi}^{(\Delta d)}_m Φ m ( Δ d ) sin \sin sin cos \cos cos
Φ m ( Δ d ) ⋅ [ sin ( ω m ⋅ k ) cos ( ω m ⋅ k ) ] = [ sin ( ω m ⋅ ( k + Δ d ) ) cos ( ω m ⋅ ( k + Δ d ) ) ] \boldsymbol{\Phi}^{(\Delta d)}_m \cdot
\begin{bmatrix}
\sin({\omega_m} \cdot k)\\
\cos({\omega_m} \cdot k)
\end{bmatrix} =
\begin{bmatrix}
\sin({\omega_m} \cdot (k+\Delta d))\\
\cos({\omega_m} \cdot (k+\Delta d))
\end{bmatrix} Φ m ( Δ d ) ⋅ [ sin ( ω m ⋅ k ) cos ( ω m ⋅ k ) ] = [ sin ( ω m ⋅ ( k + Δ d )) cos ( ω m ⋅ ( k + Δ d )) ] 很容易求得:
Φ m ( Δ d ) = [ cos ( ω m ⋅ Δ d ) sin ( ω m ⋅ Δ d ) − sin ( ω m ⋅ Δ d ) cos ( ω m ⋅ Δ d ) ] \boldsymbol{\Phi}^{(\Delta d)}_m =
\begin{bmatrix}
\cos({\omega_m} \cdot \Delta d) && \sin({\omega_m} \cdot \Delta d) \\
-\sin({\omega_m} \cdot \Delta d) && \cos({\omega_m} \cdot \Delta d)
\end{bmatrix} Φ m ( Δ d ) = [ cos ( ω m ⋅ Δ d ) − sin ( ω m ⋅ Δ d ) sin ( ω m ⋅ Δ d ) cos ( ω m ⋅ Δ d ) ] 可以惊讶的发现:Φ m ( Δ d ) \boldsymbol{\Phi}^{(\Delta d)}_m Φ m ( Δ d ) k k k Δ d \Delta d Δ d
这意味着加入到Embedding序列中的位置编码p m \boldsymbol{p}_{m} p m p n \boldsymbol{p}_{n} p n
远程衰减
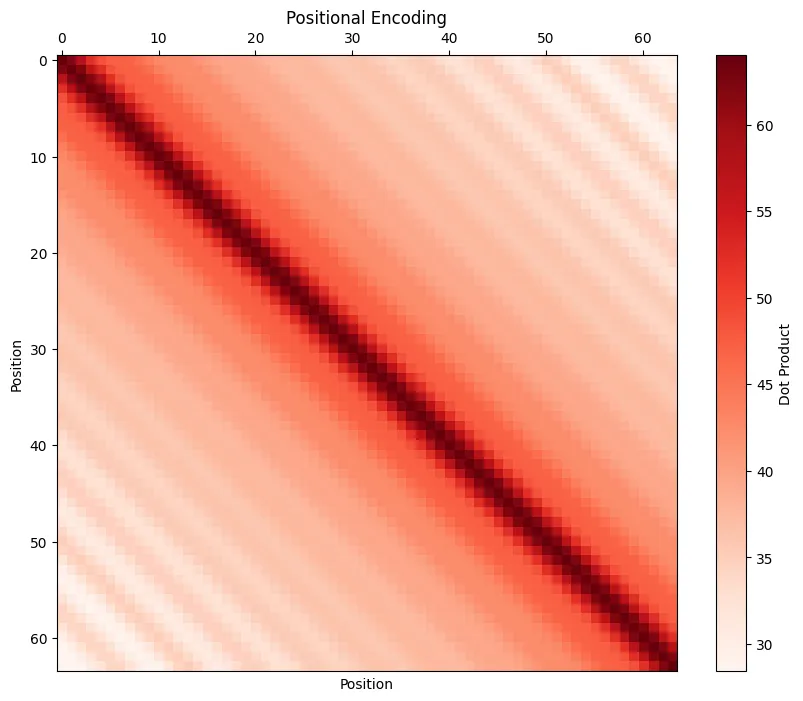
三角函数位置编码的深度解读1 0 0 0 相对距离越大的输入,其位置相关性越弱 。如果推导公式比较难,可以可视化三角函数位置编码的内积,得到类似confusion matrix的可视化矩阵,见下图。
可视化远程衰减矩阵:
相对和绝对位置编码
绝对位置编码
一般来说,绝对位置编码会加到输入序列中:在输入的第k k k x k x_k x k p k p_k p k x k + p k x_k+p_k x k + p k p k p_k p k k k k 2
相对于相对位置编码,绝对位置编码的优点是计算复杂度更低。
三角函数
在Transformer 文中,我们知道Sinusocidal位置编码在embed_sim后面接近于0 0 0 1 1 1 外推性 。
三角函数还有一个有意思的性质:sin ( i + j ) = sin i cos j + cos i sin j \sin(i+j)=\sin i\cos j+\cos i\sin j sin ( i + j ) = sin i cos j + cos i sin j cos ( i + j ) = cos i cos j − sin i sin j \cos(i+j)=\cos i \cos j - \sin i \sin j cos ( i + j ) = cos i cos j − sin i sin j i + j i+j i + j i i i j j j
可训练式
可训练式位置编码不去设计编码的形式,而是将编码作为可学习的参数,与输入向量相加。在视觉任务的Transformer工作中,例如DETR及其后续工作,都是位置编码都是可训练式。
不难想象,可训练式位置编码的缺点是没有外推性,即推理时无法处理超过训练时最长长度的输入序列。不过,苏神的文章6
相对位置编码
相对位置并没有完整建模每个输入的位置信息,而是在计算attention的时候考虑当前位置与其他位置的相对距离,由于自然语言一般更依赖于相对位置,所以相对位置编码通常有着优秀的表现 。对于相对位置编码来说,它的灵活性更大。但是,由于相对位置编码对Attention的计算进行了修改,它的计算复杂度和attention计算同样是O ( n 2 ) O(n^2) O ( n 2 )
考虑一般形式的相对位置编码4
{ q i = ( x i + p i ) W Q k j = ( x j + p j ) W K v j = ( x j + p j ) W V a i , j = s o f t m a x ( q i k j ⊤ ) o i = ∑ j a i , j v j \begin{equation}\left\{\begin{aligned}
\boldsymbol{q}_i =&\, (\boldsymbol{x}_i + \boldsymbol{p}_i)\boldsymbol{W}_Q \\
\boldsymbol{k}_j =&\, (\boldsymbol{x}_j + \boldsymbol{p}_j)\boldsymbol{W}_K \\
\boldsymbol{v}_j =&\, (\boldsymbol{x}_j + \boldsymbol{p}_j)\boldsymbol{W}_V \\
a_{i,j} =&\, softmax\left(\boldsymbol{q}_i \boldsymbol{k}_j^{\top}\right)\\
\boldsymbol{o}_i =&\, \sum_j a_{i,j}\boldsymbol{v}_j
\end{aligned}\right.\end{equation} ⎩ ⎨ ⎧ q i = k j = v j = a i , j = o i = ( x i + p i ) W Q ( x j + p j ) W K ( x j + p j ) W V so f t ma x ( q i k j ⊤ ) j ∑ a i , j v j 其中i i i j j j
我们将q i q_i q i k j k_j k j s o f t m a x softmax so f t ma x q i k j ⊤ q_i k_j^\top q i k j ⊤
q i k j ⊤ = ( x i + p i ) W Q W K ⊤ ( x j + p j ) ⊤ = ( x i W Q + p i W Q ) ( W K ⊤ x j ⊤ + W K ⊤ p j ⊤ ) \begin{equation}
\boldsymbol{q}_i \boldsymbol{k}_j^{\top} = \left(\boldsymbol{x}_i + \boldsymbol{p}_i\right)\boldsymbol{W}_Q \boldsymbol{W}_K^{\top}\left(\boldsymbol{x}_j + \boldsymbol{p}_j\right)^{\top} = \left(\boldsymbol{x}_i \boldsymbol{W}_Q + \boldsymbol{p}_i \boldsymbol{W}_Q\right)\left(\boldsymbol{W}_K^{\top}\boldsymbol{x}_j^{\top} + \boldsymbol{W}_K^{\top}\boldsymbol{p}_j^{\top}\right)
\end{equation} q i k j ⊤ = ( x i + p i ) W Q W K ⊤ ( x j + p j ) ⊤ = ( x i W Q + p i W Q ) ( W K ⊤ x j ⊤ + W K ⊤ p j ⊤ ) 作为对比,假如我们没有相对位置编码的偏置,应该是:
q i k j ⊤ = x i W Q W K ⊤ x j ⊤ \boldsymbol{q}_i \boldsymbol{k}_j^{\top}=\boldsymbol{x}_i \boldsymbol{W}_Q \boldsymbol{W}_K^{\top} \boldsymbol{x}_j^{\top} q i k j ⊤ = x i W Q W K ⊤ x j ⊤ 那么,去掉p i W Q \boldsymbol{p}_i \boldsymbol{W}_Q p i W Q p j W K \boldsymbol{p}_j \boldsymbol{W}_K p j W K R i , j K \boldsymbol{R}_{i,j}^{K} R i , j K
a i , j = s o f t m a x ( x i W Q ( x j W K + R i , j K ) ⊤ ) \begin{equation}
a_{i,j} = softmax\left(\boldsymbol{x}_i \boldsymbol{W}_Q\left(\boldsymbol{x}_j\boldsymbol{W}_K + \color{green}{\boldsymbol{R}_{i,j}^K}\right)^{\top}\right)
\end{equation} a i , j = so f t ma x ( x i W Q ( x j W K + R i , j K ) ⊤ ) 最后,在使用v i v_i v i o i = ∑ j a i , j v j = ∑ j a i , j ( x j W V + p j W V ) \boldsymbol{o}_i =\sum\limits_j a_{i,j}\boldsymbol{v}_j = \sum\limits_j a_{i,j}(\boldsymbol{x}_j\boldsymbol{W}_V + \boldsymbol{p}_j\boldsymbol{W}_V) o i = j ∑ a i , j v j = j ∑ a i , j ( x j W V + p j W V ) p j W V \boldsymbol{p}_j\boldsymbol{W}_V p j W V R i , j V \boldsymbol{R}_{i,j}^{V} R i , j V
o i = ∑ j a i , j ( x j W V + R i , j V ) \begin{equation}
\boldsymbol{o}_i = \sum_j a_{i,j}\left(\boldsymbol{x}_j\boldsymbol{W}_V + \color{green}{\boldsymbol{R}_{i,j}^{V}}\right)
\end{equation} o i = j ∑ a i , j ( x j W V + R i , j V ) 那么,R i , j K \boldsymbol{R}_{i,j}^{K} R i , j K R i , j V \boldsymbol{R}_{i,j}^{V} R i , j V ( i , j ) (i,j) ( i , j ) R i , j K , R i , j V \boldsymbol{R}_{i,j}^{K}, \boldsymbol{R}_{i,j}^{V} R i , j K , R i , j V i − j i−j i − j
R i , j K = p K [ clip ( i − j , p min , p max ) ] R i , j V = p V [ clip ( i − j , p min , p max ) ] \begin{equation}\begin{aligned}
\boldsymbol{R}_{i,j}^{K} = \boldsymbol{p}_K\left[\text{clip}(i-j, p_{\min}, p_{\max})\right] \\
\boldsymbol{R}_{i,j}^{V} = \boldsymbol{p}_V\left[\text{clip}(i-j, p_{\min}, p_{\max})\right]
\end{aligned}\end{equation} R i , j K = p K [ clip ( i − j , p m i n , p m a x ) ] R i , j V = p V [ clip ( i − j , p m i n , p m a x ) ] p K \boldsymbol{p}_K p K p V \boldsymbol{p}_V p V 可以是可训练式活三角函数式 的,都可以达到处理任意长度文本的需求。
相对位置编码还有一些形式,例如XLNET,T5或DeBERTa,都是对上面的一般式进行了一些变化2
旋转式位置编码
“一般来说,绝对位置编码具有实现简单、计算速度快等优点,而相对位置编码则直接地体现了相对位置信号,跟我们的直观理解吻合,实际性能往往也更好。由此可见,如果可以通过绝对位置编码的方式实现相对位置编码,那么就是集各家之所长。”
旋转式位置编码,英文是Rotary Position Embedding (RoPE) 是一种“绝对位置编码的方式实现相对位置编码”的设计3 RoPE应用旋转矩阵在输入序列赋予绝对位置信息,通过注意力计算(内积)赋予序列相对位置信息 。
复数的表示
矩阵表示
复数系C \mathbb{C} C R 2 \mathbb{R}^2 R 2 z z z z = a + b i z=a+bi z = a + bi i i i a a a b b b a + b i a+bi a + bi ( a , b ) (a,b) ( a , b )
a + b i ↔ ( a , b ) a+bi \leftrightarrow (a,b) a + bi ↔ ( a , b )
复数系满足加法和乘法结构:( a + b i ) + ( c + d i ) = ( a + c ) + ( b + d ) i (a+bi)+(c+di)=(a+c)+(b+d)i ( a + bi ) + ( c + d i ) = ( a + c ) + ( b + d ) i ( a + b i ) ( c + d i ) = ( a c − b d ) + ( b c + a d ) i (a+bi)(c+di)=(ac-bd)+(bc+ad)i ( a + bi ) ( c + d i ) = ( a c − b d ) + ( b c + a d ) i
复数也可以用一个2 × 2 2 \times 2 2 × 2 a + b i a+bi a + bi f f f
f ( a + b i ) = [ a − b b a ] f(a + bi) =
\begin{bmatrix}
a & -b \\
b & a
\end{bmatrix} f ( a + bi ) = [ a b − b a ] 这样定义的矩阵表示保留了复数的加法和乘法代数结构(可以将复数系C \mathbf{C} C R 2 × 2 \mathbf{R}^{2 \times 2} R 2 × 2
f ( ( a + b i ) + ( c + d i ) ) = f ( ( a + c ) + ( b + d ) i ) = [ a + c − b − d b + d a + c ] = [ a − b b a ] + [ c − d d c ] \begin{align*}
f((a + bi) + (c + di)) &= f((a + c) + (b + d) i) \\
&= \begin{bmatrix}
a + c & -b-d \\
b + d & a + c
\end{bmatrix} \\
&= \begin{bmatrix}
a & -b \\
b & a
\end{bmatrix} + \begin{bmatrix}
c & -d \\
d & c
\end{bmatrix}
\end{align*} f (( a + bi ) + ( c + d i )) = f (( a + c ) + ( b + d ) i ) = [ a + c b + d − b − d a + c ] = [ a b − b a ] + [ c d − d c ] f ( ( a + b i ) ( c + d i ) ) = f ( ( a c − b d ) + ( b c + a d ) i ) = [ a c − b d − b c − a d b c + a d a c − b d ] = [ a − b b a ] [ c − d d c ] \begin{align*}
f((a + bi) (c + di)) &= f((ac - bd) + (bc + ad) i) \\
&= \begin{bmatrix}
ac - bd & -bc-ad \\
bc + ad & ac - bd
\end{bmatrix} \\
&= \begin{bmatrix}
a & -b \\
b & a
\end{bmatrix} \begin{bmatrix}
c & -d \\
d & c
\end{bmatrix}
\end{align*} f (( a + bi ) ( c + d i )) = f (( a c − b d ) + ( b c + a d ) i ) = [ a c − b d b c + a d − b c − a d a c − b d ] = [ a b − b a ] [ c d − d c ] 另外两个复数的矩阵表示保留的是:
复数矩阵表示的行列式与复数的模长相等,都是a 2 + b 2 a^2+b^2 a 2 + b 2
复数的共轭(复数a + b i a+bi a + bi a − b i a-bi a − bi
note
为什么复数可以映射到一个2 × 2 2 \times 2 2 × 2
复数可以用矩阵表示的原因在于它们的代数结构同构于特定的2 × 2 2 \times 2 2 × 2
复数可以看作是一个二维实向量空间,基为1 1 1 i i i a + b i a + bi a + bi x + y i x + yi x + y i ( a + b i ) (a + bi) ( a + bi ) a + b i a + bi a + bi x + y i x + yi x + y i ( a x − b y ) + ( a y + b x ) i (ax - by) + (ay + bx)i ( a x − b y ) + ( a y + b x ) i x + y i x + yi x + y i [ x y ]
\begin{bmatrix}
x \\
y
\end{bmatrix} [ x y ]
[ a − b b a ] [ x y ] = [ a x − b y b x + a y ] \begin{bmatrix}
a & -b \\
b & a
\end{bmatrix}
\begin{bmatrix}
x \\
y
\end{bmatrix}=
\begin{bmatrix}
ax - by \\
bx + ay
\end{bmatrix} [ a b − b a ] [ x y ] = [ a x − b y b x + a y ] 这正是上面的矩阵形式。因此,每个复数a + b i a + bi a + bi
极坐标表示
复数z = a + b i z=a+bi z = a + bi
z = r ( sin θ + i sin θ ) z=r(\sin \theta + i\sin \theta) z = r ( sin θ + i sin θ ) 其中,r = a 2 + b 2 r=\sqrt{a^2+b^2} r = a 2 + b 2 θ = a r c t a n ( b a ) \theta=arctan(\frac{b}{a}) θ = a rc t an ( a b )
共轭使用极坐标表示:
z ‾ = r ( sin θ − i sin θ ) \overline{z} = r(\sin \theta - i\sin \theta) z = r ( sin θ − i sin θ ) 欧拉公式:
e i θ = cos θ + i sin θ e^{i\theta}=\cos \theta + i \sin \theta e i θ = cos θ + i sin θ 因此,复数可以进一步写成:
z = r e i θ z = re^{i\theta} z = r e i θ 共轭使用欧拉公式:
r e i θ ‾ = r e − i θ \overline{re^{i\theta}} = re^{-i\theta} r e i θ = r e − i θ RoPE
因为RoPE和复数的表示紧密相关,所以先对复数的表示做了铺垫,现在进入正题“旋转位置编码”。其实,从前面的章节中可以看到,三角函数编码是一种绝对位置编码,因为它提供了每个位置的确定性的编码信息,同时它也可以提供一些隐含的相对位置信息,可以说三角函数位置编码是性质非常不错的设计。但是相对位置并没有显示的去表示,RoPE是对此的改进,它是使用“绝对位置编码的方式实现相对位置编码”3 7
有位置为m m m query向量q m \mathbf{q}_m q m n n n key向量k n \mathbf{k}_n k n f f f m − n m-n m − n
对函数f f f f f f f ( q , m ) = q + p m f(q,m)=q+p_m f ( q , m ) = q + p m p m p_m p m
q ~ m = f ( q , m ) , k ~ n = f ( k , n ) \tilde{\boldsymbol{q}}_m = \boldsymbol{f}(\boldsymbol{q}, m), \quad\tilde{\boldsymbol{k}}_n = \boldsymbol{f}(\boldsymbol{k}, n) q ~ m = f ( q , m ) , k ~ n = f ( k , n ) ⟨ f ( q , m ) , f ( k , n ) ⟩ = g ( q , k , m − n ) \langle\boldsymbol{f}(\boldsymbol{q}, m), \boldsymbol{f}(\boldsymbol{k}, n)\rangle = g(\boldsymbol{q},\boldsymbol{k},m-n) ⟨ f ( q , m ) , f ( k , n )⟩ = g ( q , k , m − n ) 目的是要找到这样的函数f f f q m \boldsymbol{q}_m q m k n ∈ R 2 \boldsymbol{k}_n \in \mathbb{R}^2 k n ∈ R 2 sin \sin sin cos \cos cos
RoPE巧妙将f f f
f ( q , m ) = [ cos m θ − sin m θ sin m θ cos m θ ] [ q 0 q 1 ] \boldsymbol{f}(\boldsymbol{q}, m) =\begin{bmatrix}\cos m\theta & -\sin m\theta\\ \sin m\theta & \cos m\theta\end{bmatrix} \begin{bmatrix}q_0 \\ q_1\end{bmatrix} f ( q , m ) = [ cos m θ sin m θ − sin m θ cos m θ ] [ q 0 q 1 ] 由于一个复数既有矩阵的表示也有极坐标的表示:
f ( q , m ) = q e i m θ \boldsymbol{f}(\boldsymbol{q}, m) =
\boldsymbol{q} e^{\text{i}m\theta} f ( q , m ) = q e i m θ 把上式带入到内积计算中,并且
⟨ f ( q , m ) , f ( k , n ) ⟩ = ⟨ ( q m e i m θ ) ( k n e i n θ ) ⟩ = Re [ ( q m e i m θ ) ( k n e i n θ ) ∗ ] = Re [ q m k n ∗ e i ( m − n ) θ ] \langle\boldsymbol{f}(\boldsymbol{q}, m), \boldsymbol{f}(\boldsymbol{k}, n)\rangle=
\langle (\boldsymbol{q_m} e^{\text{i}m\theta}) (\boldsymbol{k_n} e^{\text{i}n\theta}) \rangle=
\text{Re} \left[(\boldsymbol{q_m} e^{\text{i}m\theta}) (\boldsymbol{k_n} e^{\text{i}n\theta})^{*} \right] =
\text{Re}\left[\boldsymbol{q}_m \boldsymbol{k}_n^* e^{\text{i}(m-n)\theta}\right] ⟨ f ( q , m ) , f ( k , n )⟩ = ⟨( q m e i m θ ) ( k n e i n θ )⟩ = Re [ ( q m e i m θ ) ( k n e i n θ ) ∗ ] = Re [ q m k n ∗ e i ( m − n ) θ ] 你会发现:如此定义的f f f
把二维扩展到d d d
[ cos m θ 0 − sin m θ 0 0 0 ⋯ 0 0 sin m θ 0 cos m θ 0 0 0 ⋯ 0 0 0 0 cos m θ 1 − sin m θ 1 ⋯ 0 0 0 0 sin m θ 1 cos m θ 1 ⋯ 0 0 ⋮ ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 0 0 0 0 ⋯ cos m θ d / 2 − 1 − sin m θ d / 2 − 1 0 0 0 0 ⋯ sin m θ d / 2 − 1 cos m θ d / 2 − 1 ] [ q 0 q 1 q 2 q 3 ⋮ q d − 2 q d − 1 ] \scriptsize{\begin{bmatrix}
\cos m\theta_0 & -\sin m\theta_0 & 0 & 0 & \cdots & 0 & 0 \\
\sin m\theta_0 & \cos m\theta_0 & 0 & 0 & \cdots & 0 & 0 \\
0 & 0 & \cos m\theta_1 & -\sin m\theta_1 & \cdots & 0 & 0 \\
0 & 0 & \sin m\theta_1 & \cos m\theta_1 & \cdots & 0 & 0 \\
\vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\
0 & 0 & 0 & 0 & \cdots & \cos m\theta_{d/2-1} & -\sin m\theta_{d/2-1} \\
0 & 0 & 0 & 0 & \cdots & \sin m\theta_{d/2-1} & \cos m\theta_{d/2-1} \\
\end{bmatrix} \begin{bmatrix}q_0 \\ q_1 \\ q_2 \\ q_3 \\ \vdots \\ q_{d-2} \\ q_{d-1}\end{bmatrix}} cos m θ 0 sin m θ 0 0 0 ⋮ 0 0 − sin m θ 0 cos m θ 0 0 0 ⋮ 0 0 0 0 cos m θ 1 sin m θ 1 ⋮ 0 0 0 0 − sin m θ 1 cos m θ 1 ⋮ 0 0 ⋯ ⋯ ⋯ ⋯ ⋱ ⋯ ⋯ 0 0 0 0 ⋮ cos m θ d /2 − 1 sin m θ d /2 − 1 0 0 0 0 ⋮ − sin m θ d /2 − 1 cos m θ d /2 − 1 q 0 q 1 q 2 q 3 ⋮ q d − 2 q d − 1 由于矩阵过于稀疏,使用下面公式更简洁:
[ q 0 q 1 q 2 q 3 ⋮ q d − 2 q d − 1 ] ⊗ [ cos m θ 0 cos m θ 0 cos m θ 1 cos m θ 1 ⋮ cos m θ d / 2 − 1 cos m θ d / 2 − 1 ] + [ − q 1 q 0 − q 3 q 2 ⋮ − q d − 1 q d − 2 ] ⊗ [ sin m θ 0 sin m θ 0 sin m θ 1 sin m θ 1 ⋮ sin m θ d / 2 − 1 sin m θ d / 2 − 1 ] \begin{bmatrix}q_0 \\ q_1 \\ q_2 \\ q_3 \\ \vdots \\ q_{d-2} \\ q_{d-1}
\end{bmatrix}\otimes\begin{bmatrix}\cos m\theta_0 \\ \cos m\theta_0 \\ \cos m\theta_1 \\ \cos m\theta_1 \\ \vdots \\ \cos m\theta_{d/2-1} \\ \cos m\theta_{d/2-1}
\end{bmatrix} + \begin{bmatrix}-q_1 \\ q_0 \\ -q_3 \\ q_2 \\ \vdots \\ -q_{d-1} \\ q_{d-2}
\end{bmatrix}\otimes\begin{bmatrix}\sin m\theta_0 \\ \sin m\theta_0 \\ \sin m\theta_1 \\ \sin m\theta_1 \\ \vdots \\ \sin m\theta_{d/2-1} \\ \sin m\theta_{d/2-1}
\end{bmatrix} q 0 q 1 q 2 q 3 ⋮ q d − 2 q d − 1 ⊗ cos m θ 0 cos m θ 0 cos m θ 1 cos m θ 1 ⋮ cos m θ d /2 − 1 cos m θ d /2 − 1 + − q 1 q 0 − q 3 q 2 ⋮ − q d − 1 q d − 2 ⊗ sin m θ 0 sin m θ 0 sin m θ 1 sin m θ 1 ⋮ sin m θ d /2 − 1 sin m θ d /2 − 1 其中,⊗ \otimes ⊗ θ j = 10000 − 2 j d \theta_j = 10000^{−\frac{2j}{d}} θ j = 1000 0 − d 2 j
RoPE的实现
RoPE的代码有好几种 !
苏神在roformer 有简单代码实现,和上一节最后的实现公式完全一致:
sinusoidal_pos.shape = [ 1 , seq_len, hidden_size] # Sinusoidal position embeddings
qw.shape = [batch_size, seq_len, num_heads, hidden_size] # query hiddens
kw.shape = [batch_size, seq_len, num_heads, hidden_size] # key hiddens
# 这里cos是奇数部分,sin是偶数部分,但是并且重复了一次后和原hidden_size长度一致
cos_pos = repeat_elements(sinusoidal_pos[ ... , None , 1 :: 2 ], rep = 2 , axis =- 1 )
sin_pos = repeat_elements(sinusoidal_pos[ ... , None , :: 2 ], rep = 2 , axis =- 1 )
# 首先从qw中提取出奇数和偶数索引,而qw_odd/even: [batch_size, seq_len, num_heads, D//2]
# 重要的是沿着第5维度stack,这样stack后得到的shape是 [batch_size, seq_len, num_heads, 2, D//2]
qw2 = stack([ - qw[ ... , 1 :: 2 ], qw[ ... , :: 2 ]], axis = 4 )
# reshape操作就有意思了,因为在2这个维度是奇数和偶数,reshape会原维度D,会实现交叉奇偶的效果
qw2 = reshape(qw2, shape(qw))
qw = qw * cos_pos + qw2 * sin_pos
另外有人使用pytorch实现了另一个版本 ,主要是借助公式:
[ cos m θ j − sin m θ j sin m θ j cos m θ j ] [ q 2 j q 2 j − 1 ] \begin{bmatrix}\cos m\theta_j & -\sin m\theta_j \\ \sin m\theta_j & \cos m\theta_j \end{bmatrix} \begin{bmatrix}q_{2j} \\ q_{2j-1}\end{bmatrix} [ cos m θ j sin m θ j − sin m θ j cos m θ j ] [ q 2 j q 2 j − 1 ] def apply_rotary ( x , sinusoidal_pos = None ):
if sinusoidal_pos is None :
sin, cos = sinusoidal_pos # [seq_len, hidden_dim//2]
# x.shape [batch, seq_len, hidden_dim]
x_even, x_odd = x[ ... , 0 :: 2 ], x[ ... , 1 :: 2 ]
# [cos_nθ, -sin_nθ] [x_even]
# [sin_nθ, cos_nθ] [x_odd]
# => [x_even * cos_nθ - x_odd * sin_nθ, x_even * sin_nθ + x_odd * cos_nθ]
return torch.cat([x_even * cos - x_odd * sin, x_even * sin + x_odd * cos], dim =- 1 )