由于部署和调用LLM模型需求急速增加,迅速催生了LLM推理这一领域,围绕如何加快推理速度和成本首先从学术界出现大量结合系统领域知识的工作。本文是学习LLM推理的一些笔记。
KV Cache
KV Cache是LLM推理优化中出现的第一个优化方法。理解KV Cache首先要了解LLM的推理过程的两点重要属性:1)自回归(Autoregressive),2)Causal Masking。
自回归预测即next_token会加入到之前模型的输出中,再进行下一轮的预测。代码更能说明这个过程,见注释:
@torch.no_grad()def generate(self, input_idx, max_new_tokens, temperature=1.0): "Take a input sequence of indices and complete the sequence." for _ in range(max_new_tokens): idx_cond = input_idx if input_idx.size(1) <= self.block_size else input_idx[:, :self.block_size] # model接受用户输入进行计算,也称为profile阶段 logits, _ = self(idx_cond) # 注意logits只取最后一个单词,即预测next_token logits = logits[:, -1, :] / temperature # (b, c) prob = F.(logits, dim=-1) # idx_next = F.argmax(prob, dim=-1) idx_next = torch.multinomial(prob, num_samples=1) # (b, 1) # 这一步是Autogressive,输出token会加入到in_tokens # 模型会重新对加长的in_tokens进行推理 input_idx = torch.cat((idx_cond, idx_next), dim = 1)
return input_idxmodel(in_tokens)这一步中的in_tokens会逐渐增加并重新进入model中经过Transformer中每一层进行计算,也就是说推理计算复杂度会随着in_tokens线性增加!
由于in_tokens之前的输出都是计算过的,是不是能在这里做优化呢?答案是可以,这推理过程中Attention计算中的Causal Masking有关,即使用一个上三角矩阵来遮盖掉未来的信息。这和in_tokens的优化可以用下面例子来说明下。
假设in_tokens中有目前已经有两个token,即in_tokens = [t1, t2],进入Transformer的每一层的MHA中每个head时,会将t1通过线性层映射成q1, k1, v1,然后计算注意力,为了说明问题只保留q,k,v的计算:
[q1*k1.T q1*k2.T] [1 0] [v1] = (q1 * k1.T) * v1[q2*k1.T q2*k2.T] [1 1] [v2] = (q2 * k1.T) * v1 + (q2 * k2.T) * v2然后使用(q2*k1.T)*v1+(q2*k2.T)*v2去预测下一个token,称之为t3。现在in_tokens=[t1, t2, t3],输入到模型中再次进行计算:
[q1*k1.T q1*k2.T q1*k3.T] [1 0 0] [v1] = (q1 * k1.T) * v1[q2*k1.T q2*k2.T q2*k3.T] [1 1 0] [v2] = (q2 * k1.T) * v1 + (q2 * k2.T) * v2[q3*k1.T q3*k2.T q3*k3.T] [1 1 1] [v3] = (q3 * k1.T) * v1 + (q3 * k2.T) * v2 + (q3 * k3.T) * v3我们看到,即使有q1,q2与k3的计算,但是由于causal masking,其值都无效,并且最后的输出(q3*k1.T)*v1 +(q3*k2.T)*v2+(q3* k3.T)*v3其实只与上一轮保存的k1, v1, k2, v2和当前这轮的q3, k3, v3即通过线性层映射后的结果有关。于是,我们缓存上一轮的key和value,这就是KV Cache!
KV Cache的实现是在每一层Transformer层中的Attention部分,和上一层的past_key_value(即KV Cache)直接拼接,这篇博客1的实现比较清晰:
def mha(x, c_attn, c_proj, n_head, past_key_value=None): # [n_seq, n_embd] -> [n_seq, n_embd] # qkv projection # n_seq = 1 when we pass past_key_value, so we will compute new_q, new_k and new_v x = linear(x, **c_attn) # [n_seq, n_embd] -> [n_seq, 3*n_embd]
# split into qkv qkv = np.split(x, 3, axis=-1) # [n_seq, 3*n_embd] -> [3, n_seq, n_embd]
if past_key_value: # qkv new_q, new_k, new_v = qkv # new_q, new_k, new_v = [1, n_embd] old_k, old_v = past_key_value k = np.vstack([old_k, new_k]) # k = [n_seq, n_embd], where n_seq = prev_n_seq + 1 v = np.vstack([old_v, new_v]) # v = [n_seq, n_embd], where n_seq = prev_n_seq + 1 qkv = [new_q, k, v]
current_cache = [qkv[1], qkv[2]]
# split into heads qkv_heads = list(map(lambda x: np.split(x, n_head, axis=-1), qkv)) # [3, n_seq, n_embd] -> [n_head, 3, n_seq, n_embd/n_head]
# causal mask to hide future inputs from being attended to if past_key_value: causal_mask = np.zeros((1, k.shape[0])) else: causal_mask = (1 - np.tri(x.shape[0])) * -1e10 # [n_seq, n_seq]
# perform attention over each head out_heads = [attention(q, k, v, causal_mask) for q, k, v in zip(*qkv_heads)] # [n_head, 3, n_seq, n_embd/n_head] -> [n_head, n_seq, n_embd/n_head] # merge heads x = np.hstack(out_heads) # [n_head, n_seq, n_embd/n_head] -> [n_seq, n_embd] # out projection x = linear(x, **c_proj) # [n_seq, n_embd] -> [n_seq, n_embd]
return x, current_cacheMulti-Head Attention的优化
在Multi-Head Attention中,输入序列Embedding的d_model会被切分成n_head组,然后分别经过注意力计算后再concat起来还原d_model的长度。前面KV Cache最后提到过,当输入序列非常长,KV Cache会成为显存杀手,它就成为优化的目标!
下面的Multi-Query Attention (MQA) -> Grouped-Query Attetion (GQA) -> Multi-head Latent Attention (MLA)都是对MHA的改进!
Multi-Query Attention
MQA来自于论文Fast Transformer Decoding: One Write-Head is All You Need,来自于Transformer论文的第二作者Noam Shazeer。
想法很简单:只对Query进行切分成n_head组,形状变为(b, n_heads, t, d_h),但是Key和Value直接通过线性层映射到形状(b, t, d_h),如此以来W_k和W_v的参数量急剧减少!注意,此时Key和Value和Query的形状是不能直接矩阵相乘的,可以利用广播Boardcast原则,在Key和Value的第二个维度增加1,即(b, 1, t, d_h),这样会在矩阵乘法的时候自动在n_haeds的维度扩充进行相乘。
但是,MQA有明显的缺点:性能下降严重!需要完全重新训练MQA的模型,才能带来推理速度的加快。模型训练异常昂贵,训练性能下降的MQA不太划算。
Grouped Query Attention
GQA是MHA和MQA的一般情况,其想法也很直接:如果一组Key和Value性能下降,那么多搞几组Key和Value吧。
让Deepseek对上面的mha改造成gqa:
gqa实现
def gqa(x, c_attn, c_proj, n_head, n_group, past_key_value=None): # [n_seq, n_embd] -> [n_seq, n_embd] assert n_head % n_group == 0, "n_head must be divisible by n_group"
# 计算每个头的维度 n_embd_input = x.shape[-1] d = n_embd_input // n_head # 每个头的维度
# QKV投影 x = linear(x, **c_attn) # [n_seq, n_embd_input] -> [n_seq, (n_head + 2*n_group)*d]
# 分割Q、K、V q_size = n_head * d k_size = n_group * d v_size = n_group * d
q = x[:, :q_size] k = x[:, q_size : q_size + k_size] v = x[:, q_size + k_size : q_size + k_size + v_size]
# 合并历史KV缓存 if past_key_value: old_k, old_v = past_key_value k = np.vstack([old_k, k]) v = np.vstack([old_v, v]) current_cache = [k, v]
# 分割成头 q_heads = np.split(q, n_head, axis=-1) # [n_head, n_seq, d] k_heads = np.split(k, n_group, axis=-1) # [n_group, n_seq, d] v_heads = np.split(v, n_group, axis=-1)
# 因果掩码 if past_key_value: causal_mask = np.zeros((q.shape[0], k.shape[0])) # 允许关注所有历史位置 else: causal_mask = (1 - np.tri(q.shape[0], k.shape[0])) * -1e10 # 下三角掩码
# 计算每个查询头对应的组 group_size = n_head // n_group out_heads = [] for i in range(n_head): g = i // group_size # 确定当前头所属的组 q_i = q_heads[i] k_g = k_heads[g] v_g = v_heads[g] out_head = attention(q_i, k_g, v_g, causal_mask) out_heads.append(out_head)
# 合并多头输出 x = np.hstack(out_heads)
# 输出投影 x = linear(x, **c_proj)
return x, current_cacheMulti-head Latent Attention
MLA出现在Deepseek-V2技术报告中,实现了比MHA性能好,并且KV Cache大幅降低!从下图中,体会一下从各种MHA优化的区别:
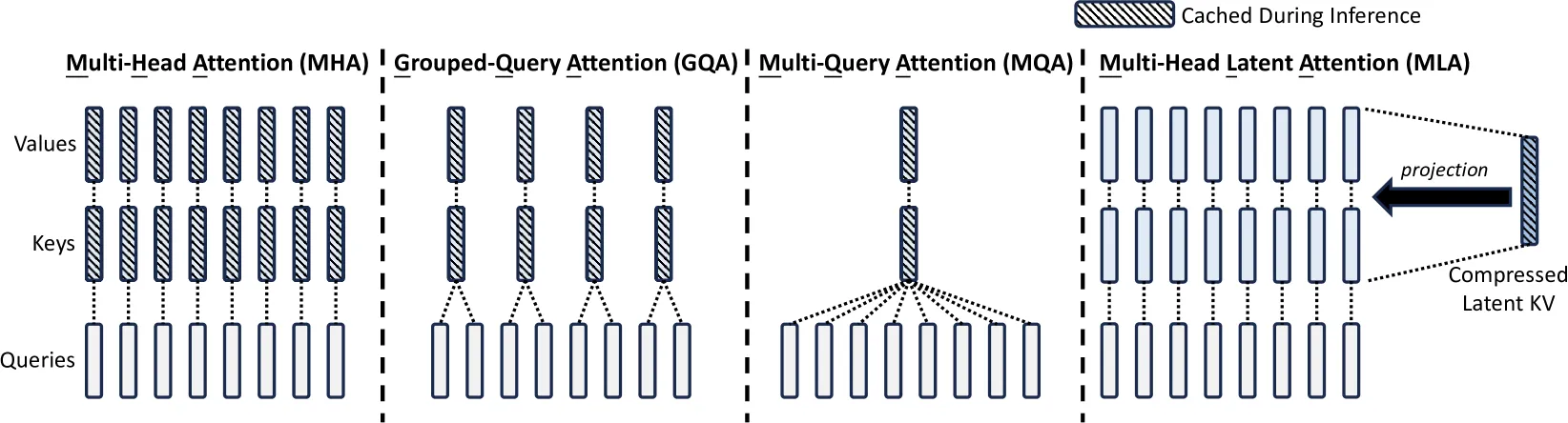
使用一个新的向量作为Key和Value共同的latent向量,的维度d_c远小于输入Embedding的维度d_model,并且只缓存这个用于推理。论文中使用一个下投影(down-projection)矩阵将输入从d_model投影到d_c,这个过程被称为Low-Rank Key-Value Joint Compression。按照苏神的文章2,其实GQA也做了低秩投影,所以它并不是MLA的主要改进点。GQA或者MQA在低秩投影后和Query相乘时,直接复制Key和Value,这相当于削弱了KV的表达。MLA使用了上投影(up-projection)将Key和Value维度又变成d_model,这样Key和Value不是简单的复制:
其中,是时刻的输入Embedding,是Key和Value共享的压缩后的向量,是down-projection(表示的是Down),矩阵 是up-projection矩阵(表示的是Up),有点像CNN中的bottleneck。
问题来了,如果最后还是还原到和并缓存,那这和原来MHA的方法一样,并没有节省推理时候的显存。实际上,在训练过程中,Key和Value和原来MHA是一样的,并没有什么优化。
但是MLA发现,如果结合注意力Attention计算的内积相乘:
你会发现两者相乘,不需要中间的和!在推理阶段可以合并为一个矩阵,只要保存。
还有怎么办?我们知道对每个Head的的输出有:
即最后还有一个线性投影将attention计算之后的值做最后的投影输出,这样最后也可以合并成一个矩阵!
至此,MLA已经实现了推理时只缓存类似MQA的,并且可以把矩阵合并到一起!另外需要说的是,最后对Query也进行了类似的压缩,虽然不能再推理时起到省KV Cache的作用,但是训练时可以省一部分激活值的内存。
但是,还有一个问题,现在MLA不支持RoPE,我们知道RoPE是一种在Attention计算时候加入的和绝对位置相关的乘性位置编码,作用于Query和Key,如果尝试给它们加入RoPE,假设RoPE的旋转矩阵是:
这样矩阵就无法合并成一个固定的矩阵了,而是带着相对位置向量矩阵。
解决方案是让Query和Key都新增,然后仅在维度上使用RoPE,而原来的维度依旧使用原MLA的矩阵乘法,文中称为Decoupled RoPE:
根据矩阵分块相乘,前维度只会自己相乘,后维度自己相乘,后维度带着相对位置关系编码。因此,需要额外的缓存中的部分。
对比下Multi-Query Attention (MQA) -> Grouped-Query Attetion (GQA) -> Multi-head Latent Attention (MLA)的缓存:
| Attention Type | KV Cache | Performance |
|---|---|---|
| Multi-Head Attention (MHA) | Strong | |
| Grouped-Query Attention (GQA) | Moderate | |
| Multi-Query Attention (MQA) | Weak | |
| MLA | Stronger |
其中,是head的数量,是head的维度,是Transformer的层数,是GQA的组数,和分别是latent向量和rope额外向量的维度,Deepseek中,
MLA的具体实现,从Deepseek官方代码中可以找到:
attn_impl: Literal["naive", "absorb"] = "absorb"class MLA(nn.Module): """ Multi-Headed Attention Layer (MLA).
Attributes: dim (int): Dimensionality of the input features. n_heads (int): Number of attention heads. n_local_heads (int): Number of local attention heads for distributed systems. q_lora_rank (int): Rank for low-rank query projection. kv_lora_rank (int): Rank for low-rank key/value projection. qk_nope_head_dim (int): Dimensionality of non-positional query/key projections. qk_rope_head_dim (int): Dimensionality of rotary-positional query/key projections. qk_head_dim (int): Total dimensionality of query/key projections. v_head_dim (int): Dimensionality of value projections. softmax_scale (float): Scaling factor for softmax in attention computation. """ def __init__(self, args: ModelArgs): super().__init__() self.dim = args.dim self.n_heads = args.n_heads self.n_local_heads = args.n_heads // world_size self.q_lora_rank = args.q_lora_rank self.kv_lora_rank = args.kv_lora_rank # d_c self.qk_nope_head_dim = args.qk_nope_head_dim self.qk_rope_head_dim = args.qk_rope_head_dim #d_r self.qk_head_dim = args.qk_nope_head_dim + args.qk_rope_head_dim self.v_head_dim = args.v_head_dim
if self.q_lora_rank == 0: self.wq = ColumnParallelLinear(self.dim, self.n_heads * self.qk_head_dim) else: self.wq_a = Linear(self.dim, self.q_lora_rank) # W^DQ self.q_norm = RMSNorm(self.q_lora_rank) # Norm只用在了d_c,没有用在d_r self.wq_b = ColumnParallelLinear(self.q_lora_rank, self.n_heads * self.qk_head_dim) # W^UQ self.wkv_a = Linear(self.dim, self.kv_lora_rank + self.qk_rope_head_dim) # W*DKV self.kv_norm = RMSNorm(self.kv_lora_rank) self.wkv_b = ColumnParallelLinear(self.kv_lora_rank, self.n_heads * (self.qk_nope_head_dim + self.v_head_dim)) self.wo = RowParallelLinear(self.n_heads * self.v_head_dim, self.dim) self.softmax_scale = self.qk_head_dim ** -0.5 if args.max_seq_len > args.original_seq_len: mscale = 0.1 * args.mscale * math.log(args.rope_factor) + 1.0 self.softmax_scale = self.softmax_scale * mscale * mscale
if attn_impl == "naive": self.register_buffer("k_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.qk_head_dim), persistent=False) self.register_buffer("v_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.v_head_dim), persistent=False) else: self.register_buffer("kv_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.kv_lora_rank), persistent=False) self.register_buffer("pe_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.qk_rope_head_dim), persistent=False)
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]): """ Forward pass for the Multi-Headed Attention Layer (MLA).
Args: x (torch.Tensor): Input tensor of shape (batch_size, seq_len, dim). start_pos (int): Starting position in the sequence for caching. freqs_cis (torch.Tensor): Precomputed complex exponential values for rotary embeddings. mask (Optional[torch.Tensor]): Mask tensor to exclude certain positions from attention.
Returns: torch.Tensor: Output tensor with the same shape as the input. """ bsz, seqlen, _ = x.size() end_pos = start_pos + seqlen if self.q_lora_rank == 0: q = self.wq(x) else: q = self.wq_b(self.q_norm(self.wq_a(x))) q = q.view(bsz, seqlen, self.n_local_heads, self.qk_head_dim) q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1) q_pe = apply_rotary_emb(q_pe, freqs_cis) kv = self.wkv_a(x) kv, k_pe = torch.split(kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1) k_pe = apply_rotary_emb(k_pe.unsqueeze(2), freqs_cis) if attn_impl == "naive": q = torch.cat([q_nope, q_pe], dim=-1) kv = self.wkv_b(self.kv_norm(kv)) kv = kv.view(bsz, seqlen, self.n_local_heads, self.qk_nope_head_dim + self.v_head_dim) k_nope, v = torch.split(kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1) k = torch.cat([k_nope, k_pe.expand(-1, -1, self.n_local_heads, -1)], dim=-1) self.k_cache[:bsz, start_pos:end_pos] = k self.v_cache[:bsz, start_pos:end_pos] = v scores = torch.einsum("bshd,bthd->bsht", q, self.k_cache[:bsz, :end_pos]) * self.softmax_scale else: wkv_b = self.wkv_b.weight if self.wkv_b.scale is None else weight_dequant(self.wkv_b.weight, self.wkv_b.scale, block_size) wkv_b = wkv_b.view(self.n_local_heads, -1, self.kv_lora_rank) q_nope = torch.einsum("bshd,hdc->bshc", q_nope, wkv_b[:, :self.qk_nope_head_dim]) self.kv_cache[:bsz, start_pos:end_pos] = self.kv_norm(kv) self.pe_cache[:bsz, start_pos:end_pos] = k_pe.squeeze(2) scores = (torch.einsum("bshc,btc->bsht", q_nope, self.kv_cache[:bsz, :end_pos]) + torch.einsum("bshr,btr->bsht", q_pe, self.pe_cache[:bsz, :end_pos])) * self.softmax_scale if mask is not None: scores += mask.unsqueeze(1) scores = scores.softmax(dim=-1, dtype=torch.float32).type_as(x) if attn_impl == "naive": x = torch.einsum("bsht,bthd->bshd", scores, self.v_cache[:bsz, :end_pos]) else: x = torch.einsum("bsht,btc->bshc", scores, self.kv_cache[:bsz, :end_pos]) x = torch.einsum("bshc,hdc->bshd", x, wkv_b[:, -self.v_head_dim:]) x = self.wo(x.flatten(2)) return x